This page describes the syntax for setting up and running predictions, as well as how to design a prediction model appropriate for your needs. It assumes that you have fulfilled all the prerequisites for Prediction API usage .
Before reading this page, we highly recommend that you try the Hello World example to get a better idea of how the Prediction API works.
Contents
Using the API
Here are the main steps in using the Prediction API:
- Create your training data. You must create training data that is appropriate for the question that you want to answer. This is the most critical and complex step; you should spend time designing the appropriate training data for your needs. You could also use a pre-trained model from the hosted model gallery and skip right to step 4: sending a prediction query.
- Upload your training data to Google Cloud Storage using standard Google Cloud Storage tools.
- Train the API against the data. Call the Prediction API training method, passing in the location of your training data. You must poll the Prediction API to see when it is finished training.
- Send a prediction query . The Prediction API will return an answer that is either an estimated numeric value, or a categorization of your query object, depending on your training data.
- [ Optional ] Send additional data to your model. If you have a steady stream of new training data that you'd like to add to your model, you can add new examples to your existing model individually, instead of uploading all your data at once. This helps improve your model quickly, as new data becomes available.
The two most important aspects of using the Prediction API are creating an appropriate question that the API can answer, and then creating and structuring appropriate data to use to train the API to answer that question. In order to do this, let's first explain what prediction is, and how it works.
What is "Prediction?"
The term "prediction" might seem a little misleading, because the Prediction API can actually perform two specific tasks:
- Given a new item, predict a numeric value for that item, based on similar valued examples in its training data.
- Given a new item, choose a category that describes it best , given a set of similar categorized items in its training data.
It might seem that you couldn't do very much with these two basic capabilities. However, if you design your question well, and choose your data carefully, you can actually use the engine to predict what a user will like or what a future value will be, as well as many other useful tasks.
Examples, Please!
Here are two simple examples of how to use the ability to quantify or categorize an item in order to produce a useful service:
Regression (Numeric) values
Imagine that you have the following training data:
Temperature City Day_of_year Weather 52 "Seattle" 283 "cloudy" 64 "Seattle" 295 "sunny" 60 "Seattle" 287 "partly_cloudy" ...
If you have enough data points, and you sent the query "Seattle,288,sunny", you might get the value 63 back as a temperature estimate, as the Prediction API estimates a value from the most similar conditions. With this system, the Prediction API compares your query to existing examples, and estimates a value for your query, based on closeness to existing examples. Numeric values are calculated, and do not need to match any existing values in the training data.
The term for this type of prediction, which returns a numeric value, is a regression model . Regression models estimate a numeric answer for a question given the closeness of the submitted query to the existing examples.
We use a number for the day of year rather than a date or a string date (e.g., "2010-10-15" or "October 15") because the Prediction API only understands numbers and strings. If we used a string ("October 15"), the API is unable to parse and understand that as a date, so it would be unable to make the connection that "October 15" is between "October 14" and "October 22" and estimate a temperature between those values. The API can understand that 288 is between 287 and 295.
Categorization values
Now imagine that you have a set of training data that includes email subject lines and a description of the corresponding email, like this:
Description Subject line "spam" "Get her to love you" "spam" "Lose weight fast!" "spam" "Lowest interest rates ever!" "ham" "How are you?" "ham" "Trip to New York" ...
If you send the query "You can lose weight now!" you would probably get the result "spam". You could use this to create a spam filter for your email system. With this system, the Prediction API compares your query to existing entries, and tries to guess the category (the first column value) that best describes it, given the categories assigned to similar items.
The term for this second type of prediction, which returns a string value, is a categorical model . Categorical models determine the closest category fit for a submitted example among all the examples in its training data. The Hello World example as well as the spam detection example here are categorical models. When you submit a query, the API tries to find the category that most closely describes your query. In the Hello World example, the query "mucho bueno" returns the result
...Most likely: Spanish, Full results: [
{"label":"French","score":-46.33},
{"label":"Spanish","score":-16.33},
{"label":"English","score":-33.08}
]
Where the most likely category is listed, along with the relative closeness of all categories, where the larger (more positive) the number, the closer the match.
A more complicated training for a categorical system could even help you create an email forwarder that evaluates the contents of a message and forwards it to an appropriate person or department.
The key to designing a prediction system that answers your question is to formulate your question as either numeric or categorical, and design proper training data to answer that question. This is what we'll discuss next.
Training Your Model
In order to use the Prediction API, you must first train it against a set of training data. At the end of the training process, the Prediction API creates a model for your data set. Each model is either categorical (if the answer column is string) or regression (if the answer column is numeric). The model remains until you explicitly delete it. The model learns only from the original training session and any Update calls; it does not continue to learn from the Predict queries that you send to it.
Training data can be submitted in one of the following ways:
- A comma-separated value (CSV) file. Each row is an example consisting of a collection of data plus an answer (a category or a value) for that example, as you saw in the two data examples above. All answers in a training file must be either categorical or numeric; you cannot mix the two. After uploading the training file, you will tell the Prediction API to train against it.
- Training instances embedded directly into the request. The training instances can be embedded into the trainingInstances parameter. Note: due to limits on the size of an HTTP request, this would only work with small datasets (< 2 MB).
- Via Update calls. First an empty model is trained by passing in empty storageDataLocation and trainingInstances parameters into an Insert call. Then, the training instances are passed in using the Update call to update the empty model. Note: since not all classifiers can be updated, this may result in lower model accuracy than batch training the model on the entire dataset.
Important: Note that you must have access to the training data file on Google Cloud Storage to be able to train your model from a CSV file, and the user submitting the request must have write permissions for the project under which the model will be stored.
After training is done, you can submit a query to your model. All queries are submitted to a specific model identified by a unique ID (supplied by you) and project number . The query that you send is similar in form to a single training entry: that is, it has the same columns, but the query does not include the answer column. The Prediction API uses the patterns that it found in the training data to either find the closest category for the submitted example (if this is a categorical model) or estimate a value for the example (if this is a regression model), based on your training data, and returns the category or value. After training you can update the model with additional examples .
The key to using the Prediction API is structuring your training data so that it can return an answer that you can use meaningfully, and that it includes any data that might be causally related to that answer. We will discuss the details of the training data next.
Note: We do not describe the actual logic of the Prediction API in these documents, because that system is constantly being changed and improved. Therefore we can't provide optimization tips that depend on specific implementations of our matching logic, which can change without notice.
Structuring the Training Data
Think of the training data as a table. This table consists of a set of examples (rows). Each example has a collection of numeric or text features (columns) that describe the example. Each example also has a single value, the "answer" that you have assigned to that example. The value can be either numeric or a string category. A training table has one example value column (the first column), and one or more feature columns (all the remaining columns). There is no limit to how many columns your table can have.
The Prediction API works by comparing a new example (your query) to the examples from the training set, and then finding the category that this new item matches best, or estimating a value by closest matches (depending on the model type). Therefore, the more features you include in the data, the more signals the Prediction API has to try to find matches.
The following diagram shows training data for a model that will be used to predict a person's height, based on their gender, parents' heights, and national origin. This table has five examples, each representing a measured person. Each example has the following columns: "Height in meters", "Gender", "Father's height", "Mother's height", "Country of origin". Note that the training data file does not actually have row headers, string values are surrounded by quotation marks, and cell values are separated by commas.
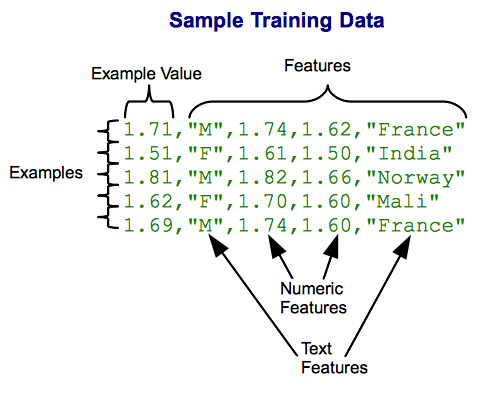
This table is just a small example; good training data should include a minimum of several hundred examples. However, the more examples, the more accurate the prediction: thousands, even millions of examples are common in big systems.
To improve the match results, we could increase the number of examples, and also increase the number of features. For example, the previous table could also include the current country of residence of the person, their calcium intake, and so on. Or, in the spam detection model, we could include the number of external links in the email, the number of images, and the number of large attachments.
You can see some example training data for different usage scenarios, and walk through the design process, on the Scenarios page. We have summarized some basic design principles below.
Training Data File Format
Training data file is uploaded to Google Cloud Storage as a CSV (comma-separated value) file. Think of this file as a table, with each row representing one example, and commas separating columns. The first column is the example value, and all additional columns are features.
Empty cells will not cause an error, but you should avoid having empty cells because an empty string cell evaluates to "" (text features) or zero (numeric features), which will throw off the matching algorithm. There is no way to differentiate "unknown value" from zero or "" in the data.
After training a model from a data file, you can add additional training data to a model data using streaming training . You can also delete model.
The CSV training file must follow these conventions:
- Maximum file size is 2.5GB
- You must have a minimum of six examples in your training file
- No header row is allowed
- Only one example is allowed per line. A single example cannot contain newlines, and cannot span multiple lines.
- Columns are separated by commas. Commas inside a quoted string are not column delimiters.
- The first column represents the value (numeric or string) for that example. If the first column is numeric, this model is a regression model; if the first column is a string, it is a categorization model. Each column must describe the same kind of information for that example.
- The column order of features in the table does not weight the results; the first feature is not weighted any more than the last.
- As a best practice, remove punctuation (other than apostrophes ' ) from your data. This is because commas, periods, and other punctuation rarely add meaning to the training data, but are treated as meaningful elements by the learning engine. For example, "end." is not matched to "end".
-
Text strings
:
- Place double quotes around all text strings.
- Text matching is case-sensitive: "wine" is different from "Wine."
- If a string contains a double quote, the double quote must be escaped with another double quote, for example: "sentence with a ""double"" quote inside"
- Strings are split at whitespace into component words as part of the prediction matching. That is, "Godzilla vs Mothra" will be split into "Godzilla", "vs", and "Mothra" when searching for closest matches. If you require a string to remain unsplit, such as for proper names or titles, use underscores or some other character instead of whitespace between words. For example: Godzilla_vs_Mothra. If you want to assign a set of labels to a single feature, simply include the labels: for example, a genre feature of a movie entry might be "comedy animation black_and_white". The order of words in a string also does not affect matching value, only the quantity of matched words.
- Quoting a substring does not guarantee an exact match. That is, placing quotes around the phrase "John Henry" will not force matches only with "John Henry"; "John Henry" has partial matches to both "John" and "Henry". However, more matches per string generates a higher score, so "John Henry" will match "John Henry" best.
-
Numeric values
:
- Both integer and decimal values are supported.
-
Numbers in quotes without whitespace will be treated as numbers, even if they are in quotation marks. Multiple numeric values within quotation marks in the same field will be treated as a string. For example:
- Numbers: "2", "12", "236"
- Strings: "2 12", "a 23"
Using a Hosted Model
The Prediction API hosts a gallery of user-submitted models that you can use. This is convenient if you don't have the time, resources, or expertise to build a model for a specific topic. You can see a list of hosted models in the Prediction Gallery .
The only method call supported on a hosted model is predict . The gallery will list the URL required for a prediction call to a specific model. If a model is not free to use, your project must have billing enabled in the Developers Console.
Note that hosted models are versioned; this means that when a model is retrained, it will get a new path that includes the version number. Periodically check the gallery to ensure that you're using the latest version of a hosted model. The model version number appears in the access URL. Different versions might return different scores for the same input.
General Usage Notes
Here are some general tips for using the Prediction API.
Authorizing requests
Every request your application sends to the Google Prediction API must include an authorization token. The token also identifies your application to Google.
About authorization protocols
Your application must use OAuth 2.0 to authorize requests. No other authorization protocols are supported.