
MapReduce is a programming model for processing large amounts of data in a parallel and distributed fashion. It is useful for large, long-running jobs that cannot be handled within the scope of a single request, tasks like:
- Analyzing application logs
- Aggregating related data from external sources
- Transforming data from one format to another
- Exporting data for external analysis
With the App Engine MapReduce library, your code can run efficiently and scale automatically. App Engine takes care of the details of partitioning the input data, scheduling execution across a set of machines, handling failures, and reading/writing to the Google Cloud platform.
- Overview
- Jobs
- Stages
- Sharding: Parallel Processing
- Slicing: Distributed Scheduling and Fault Tolerance
- Comparison with Hadoop
Overview
App Engine MapReduce is an open-source library that is built on top of App Engine services, including Datastore and Task Queues. You must download the MapReduce library and include it with your application. The library provides:
- A programming model for large-scale distributed data processing
- Automatic parallelization and distribution within your existing codebase
- Access to Google-scale data storage
- I/O scheduling
- Fault-tolerance, handling of exceptions
- User-tunable settings to optimize for speed/cost
- Tools for monitoring status
There are no usage charges associated with the MapReduce library. As with any App Engine application, you are charged for any App Engine resources that the library or your MapReduce code consumes (beyond the free quotas) while running your job. These can include instance hours, Datastore and Google Cloud Storage usage, network, and other storage.
Jobs
When you use the MapReduce library, you create a job. A job is composed of one or more stages . There are two kinds of jobs; both use the MapReduce library's sharding and slicing capabilities (discussed below) to efficiently operate on large data sets.
Map Job
A Map job provides a simple and efficient way to perform parallel processing on large data sets. It consists of a single map stage. You only need to write one function that emits output for an input item, or acts upon the input as it is consumed, or does both. Map jobs can be used for tasks like migrating data, gathering statistics, and backing up or deleting files.
The data flow for a Map job looks like this:

MapReduce Job
A MapReduce job has three stages: map, shuffle, and reduce. Each stage in the sequence must complete before the next one can run. Intermediate data is stored temporarily between the stages. The map stage transforms single input items to key-value pairs, the shuffle stage groups values with the same key together, and the reduce stage processes all the items with the same key at once. The map-shuffle-reduce algorithm is very powerful because it allows you to process all the items (values) that share some common trait (key), even when there is no way to access those items directly because, for instance, the trait is computed.
The data flow for a MapReduce job looks like this:

Stages
Map
The MapReduce library includes a Mapper class that performs the map stage. The map stage uses an input reader that delivers data one record at a time. The library also contains a collection of Input classes that implement readers for common types of data. You can also create your own reader, if needed.
The map stage uses a map() function that you must implement. When the map stage runs, it repeatedly calls the reader to get one input record at a time and applies the map() function to the record.
The implementation of the map() function depends on the kind of job you are running. When used in a Map job, the map() function emits output values. When used in a map reduce job, the map() function emits key-value pairs for the shuffle stage.
When emitting pairs for a MapReduce job, the keys do not have to be unique. The same key can appear in many pairs. For example, assume the input is a dog database that contains records listing license id, breed, and name:
14877 poodle muffy
88390 beagle dotty
73205 collie pancakes
95782 beagle esther
77865 collie lassie
75093 poodle albert
24798 poodle muffy
13334 collie lassie
A MapReduce job that computes the most popular name for each breed has a map() function that pairs each dog's name with its breed and emits these pairs:
(poodle, muffy)
(beagle, dotty)
(collie, pancakes)
(beagle, esther)
(collie, lassie)
(poodle, albert)
(poodle, muffy)
(collie, lassie)
Shuffle
The shuffle stage first groups all the pairs with the same key together:
(poodle, muffy)
(poodle, albert)
(poodle, muffy)
(beagle, dotty)
(beagle, esther)
(collie, pancakes)
(collie, lassie)
(collie, lassie)
and then outputs a single list of values for each key:
(poodle, [muffy, albert, muffy])
(beagle, [dotty, esther])
(collie, [pancakes, lassie, lassie])
If the same key-value pair occurs more than once, the associated value will appear multiple times in the shuffle output for that key. Also note that the list of values is not sorted.
The shuffle stage uses a Google Cloud Storage bucket, either the default bucket or one that you can specify in your setup code.
Reduce
The MapReduce library includes a Reducer class that performs the reduce stage. The reduce stage uses a reduce() function that you must implement. When this stage executes, the reduce() function is called for each unique key in the shuffled intermediate data set. The reduce function takes a key and the list of values associated with that key and emits a new value based on the input. For example, a reduce function that determines the most popular name for each breed would take the input:
(collie, [pancakes, lassie, lassie])
count the number of times each unique name appears in the list, and output the string:
collie: lassie
The reduce output is passed to the output writer. The MapReduce library includes a collection of Output classes that implement writers for common types of output targets. You can also create your own writer, if needed.
Sharding: Parallel Processing
Sharding divides the input of a stage into multiple data sets ( shards ) that are processed in parallel. This can significantly improve the time it takes to run a stage. When running a MapReduce job, all the shards in a stage must finish before the next stage can run.
When a map stage runs, each shard is handled by a separate instance of the Mapper class, with its own input reader. Similarly, for a reduce stage, each shard is handled by a separate instance of the Reducer class with its own output writer. The shuffle stage also shards its input, but without using any user-specified classes.
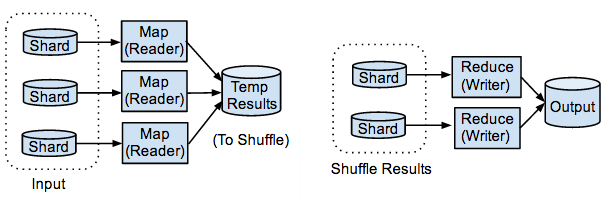
The number of shards used in each stage can be different. The implementation of the input and output classes determines the number of map and reduce shards respectively. The diagram below shows the map stage handling its input in three shards, and the reduce stage using two shards.
Slicing: Distributed Scheduling and Fault Tolerance
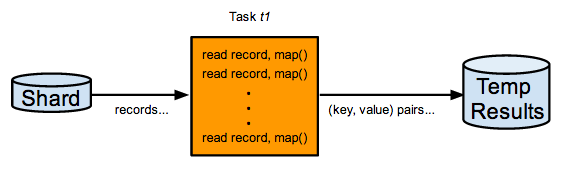
The data in a shard is processed sequentially. The job executes a consecutive series of tasks using an App Engine task queue, one task at a time per shard. When a task runs, it reads data from the associated shard and calls the appropriate function (map, shuffle, or reduce) as many times as possible in a configurable time interval. The data processed in a task is called a slice . The amount of data consumed in a slice can vary, depending on how quickly the function processes its input. When a slice is completed, another task is enqueued for the next slice on the shard. The process repeats until all data in the shard has been processed. The diagram below shows a task in the map stage consuming a slice of a shard with repeated read/map calls:
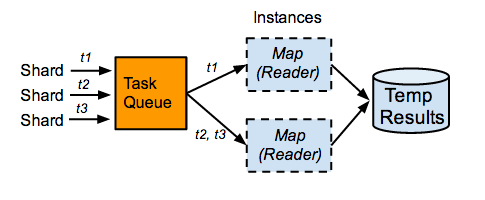
The tasks for all shards are placed in a single task queue. App Engine dynamically determines how many instances of a module to spin up in order to handle the task load. The number of instances may change while a stage is running. The diagram below shows a moment in time during the map stage when only two instances of the module running the Map are handling the three current tasks (t1, t2, t3) associated with the shards.
The use of task queues, along with dynamic instance scaling, helps to distribute the workload efficiently and transparently. Dividing execution into slices also offers a level of fault tolerance. Without slicing, if an error occurs while processing a shard, that entire shard would need to be re-run. With execution broken into slices, it is possible to detect the failure of a slice and attempt to re-run the slice a number of times before declaring a complete failure of the shard, possibly starting the shard again, or failing the entire job.
Comparison with Hadoop
While Hadoop and the App Engine MapReduce library are similar in function, there are differences between the implementations, summarized in the table below:
| Hadoop | App Engine | |
|---|---|---|
| Partitioning Data |
Hadoop itself partitions the input data into shards (aka splits). The user specifies the number of reducers. The data in each shard is handled in a separate task. Hadoop tasks are often data-bound. The amount of data each task processes is frequently predetermined when the job starts. Large Hadoop jobs tend to have more map and reduce shards than an equivalent job in App Engine. |
The number of input and reducer shards is determined by the Input and Output classes that you use. The data for each shard can be handled by multiple tasks, as explained in slicing, above. |
| Controlling Multiple Jobs | The scheduler can be controlled by setting the priority of each job. Higher priority jobs may preempt lower priority jobs that started first. | Multiple jobs run concurrently. The amount of parallelism is controlled by the module configuration and task queue settings . |
| Scaling and Persistence | Hadoop clusters tend to be long lived and may persist when there are no running jobs. | App Engine scales dynamically, and typically does not consume resources when nothing is running. |
| Combiners |
Hadoop supports
combiners
.
|
App Engine does not support combiners. Similar work can be performed in your reduce() method. |
| Data Storage | Input, output, and intermediate data (between map and reduce stages) may be stored in HDFS. | Input, output, and intermediate data may be stored in Google Cloud Storage. |
| Fault tolerance | The task for each split (shard) can fail and be retried independently. | Retry handling exists at both the shard and slice level. |
| Starting Jobs | RPC over HTTP to the Job Tracker. | Method call that can be invoked from any App Engine application. |
| Controlling Jobs | Job Tracker maintains state for all running jobs. There is a risk that the Job Tracker can become overwhelmed. | State is distributed in the datastore and task queues. There is no single point of failure. |