The MapReduce library comes with an App Engine project that runs two examples using the MapReduce library:
-
RandomCollisions is a single MapReduce job that tests the Java
random number generator. It looks for collisions: seed values that produce the
same output when
next()is called the first time. (It does not find any.) - EntityCount runs three jobs in a row: first a Map job that creates entities in Google Cloud Datastore, next, a MapReduce job that analyzes the entities, and finally, another Map job that deletes the entities.
Downloading and running the examples
The source code for the examples is included in the MapReduce open source project. Download the entire project with this command:
svn checkout http://appengine-mapreduce.googlecode.com/svn/trunk/java
Then cd to the java directory you downloaded and compile the project using ant. This command also compiles the MapReduce library and installs its jars in the project:
ant compile_example
Finally, run the example in the development server. The
dev_appserver
command is located in the App Engine SDK's
bin
directory:
dev_appserver.sh example/
To start the map-reduce, point your browser at
http://localhost:8080
. You will be asked to login:
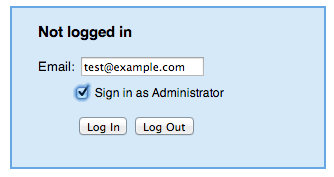
Enter an email address, and be sure to check Sign in as Administrator .
You'll see the demo app's landing page:

To run the random collisions example, click on its Run the example link. A form appears:

Fill in the four fields and press Start MapReduce and the job will run.
The project directories
The top-level example directory is an EAR hierarchy that has a META-INF directory and two WAR directories (default and mapreduce) that define two modules.
META-INF directory
This directory contains the file
application.xml
which declares the two modules.
The default module and its directory
The default directory defines the default module, which is the app's frontend. The WEB-INF directory contains the .xml configuration files. Particular features to note are:
-
appengine-web.xmlsets the default module's instance class to F2. -
queue.xmldefines a queue for the MapReduce job. -
web.xmlincludes a<security-constraint>on all URLs, and also defines the top-level servletrandomcollisionswhich will start the example CollisionFindingServlet. Note that the servlet runs in the default module, but the MapReduce job that it starts will run in the mapreduce module, because the code that sets up the job callssetModule().
The mapreduce module and its directory
The mapreduce directory defines the mapreduce module, which contains the source code for both jobs. Features to note:
-
appengine-web.xmlsets the module's instance class to F4. -
web.xmlcontains only the two servlets required to run the MapReduce jobs.
The RandomCollisions example
The source code for this example is in the directory example/src/com/google/appengine/demos/mapreduce/randomcollisions.
CollisionFindingServlet.java
The static method
createMapReduceSpec()
creates a
MapReduceSpecification
. Note that it uses
Mapper
and
Reducer
classes that are defined in other source files. It also uses existing MapReduce classes for the Marshallers and to handle input and output.
public static MapReduceSpecification<Long, Integer, Integer, ArrayList<Integer>,
GoogleCloudStorageFileSet> createMapReduceSpec(String bucket, long start, long limit,
int shards) {
ConsecutiveLongInput input = new ConsecutiveLongInput(start, limit, shards);
Mapper<Long, Integer, Integer> mapper = new SeedToRandomMapper();
Marshaller<Integer> intermediateKeyMarshaller = Marshallers.getIntegerMarshaller();
Marshaller<Integer> intermediateValueMarshaller = Marshallers.getIntegerMarshaller();
Reducer<Integer, Integer, ArrayList<Integer>> reducer = new CollisionFindingReducer();
Marshaller<ArrayList<Integer>> outputMarshaller = Marshallers.getSerializationMarshaller();
Output<ArrayList<Integer>, GoogleCloudStorageFileSet> output = new MarshallingOutput<>(
new GoogleCloudStorageFileOutput(bucket, "CollidingSeeds-%04d", "integers"),
outputMarshaller);
MapReduceSpecification<Long, Integer, Integer, ArrayList<Integer>, GoogleCloudStorageFileSet>
spec = new MapReduceSpecification.Builder<>(input, mapper, reducer, output)
.setKeyMarshaller(intermediateKeyMarshaller)
.setValueMarshaller(intermediateValueMarshaller)
.setJobName("DemoMapreduce")
.setNumReducers(shards)
.build();
return spec;
}
The method
getSettings()
sets the taskqueue to the queue defined in the
queue.xml
file, and the module to the mapreduce module.
public static MapReduceSettings getSettings(String bucket, String queue, String module) {
MapReduceSettings settings = new MapReduceSettings.Builder()
.setBucketName(bucket)
.setWorkerQueueName(queue)
.setModule(module) // if queue is null will use the current queue or "default" if none
.build();
return settings;
}
The
doPost()
method runs a MapReduce job with parameters entered by the user. It creates a MapReduce job and starts it by calling MapReduceJob.start(). The job will run in the mapreduce module.
MapReduceSpecification<Long, Integer, Integer, ArrayList<Integer>, GoogleCloudStorageFileSet>
mapReduceSpec = createMapReduceSpec(bucket, start, limit, shards);
MapReduceSettings settings = getSettings(bucket, queue, module);
String id = MapReduceJob.start(mapReduceSpec, settings);
SeedToRandomMapper.java
This class defines the
map()
method for the job. It emits a key-value pair where the value is the seed used to generate a random sequence, and the key is the first number in the sequence.
public void map(Long sequence) {
Random r = new Random(sequence);
emit(r.nextInt(), Ints.checkedCast(sequence));
}
CollisionFindingReducer.java
This class defines the
reduce()
method for the job. A collision occurs when there is a key with an associated list of values that has more than one seed value for the same random number.
public void reduce(Integer valueGenerated, ReducerInput<Integer> seeds) {
ArrayList<Integer> collidingSeeds = Lists.newArrayList(seeds);
if (collidingSeeds.size() > 1) {
LOG.info("Found a collision! The seeds: " + collidingSeeds
+ " all generaged the value " + valueGenerated);
emit(collidingSeeds);
}
}
The EntityCount example
The source code for this example is in the directory example/src/com/google/appengine/demos/mapreduce/entitycount. This example links three consecutive jobs together using the pipeline API which is still evolving. We include it here because the first and last job in the pipeline provide an example of how to specify Map jobs.
EntityCreator.java
This file subclasses
MapOnlyMapper
, which is used in a Map job to create random
entities in the Datastore.
DeleteEntityMapper.java
This file subclasses
MapOnlyMapper
, which is used in a Map job to remove entities
from the Datastore. Note that it does not emit any output.
ChainedMapReduceJob.java
This file creates three jobs, each one is defined by its own job specification.
The specifications are created with the methods
getCreationJobSpec()
,
getCountJobSpec()
, and
getDeleteJobSpec()
.